
Robotic Table Wiping via Reinforcement Learning and Whole-body Trajectory Optimization
T. Lew, S. Singh, M. Prats, J. Bingham, J. Weisz, B. Holson, X. Zhang, V. Sindhwani, Y. Lu, F. Xia, P. Xu, T. Zhang, J. Tan, M. Gonzalez
Published in ICRA - January 2023

Operating in the real world requires handling high-dimensional sensory inputs and dealing with the stochasticity of the environment. In this work, we propose a framework to enable multipurpose assistive mobile robots to autonomously wipe tables to clean spills and crumbs.

This problem is challenging for both high-level planning and low-level control. Indeed, at a high-level, deciding how to best wipe a spill perceived by a camera requires solving a challenging planning problem with stochastic dynamics. At a low-level, executing a wiping motion requires simultaneously maintaining contact with the table while avoiding nearby obstacles such as chairs.
Our approach combines the strengths of reinforcement learning (RL) - planning in high-dimensional observation spaces with complex stochastic dynamics, and of trajectory optimization - guaranteeing constraints satisfaction while executing whole-body trajectories. It does not require collecting a task-specific dataset on the system and transfers zero-shot to hardware.
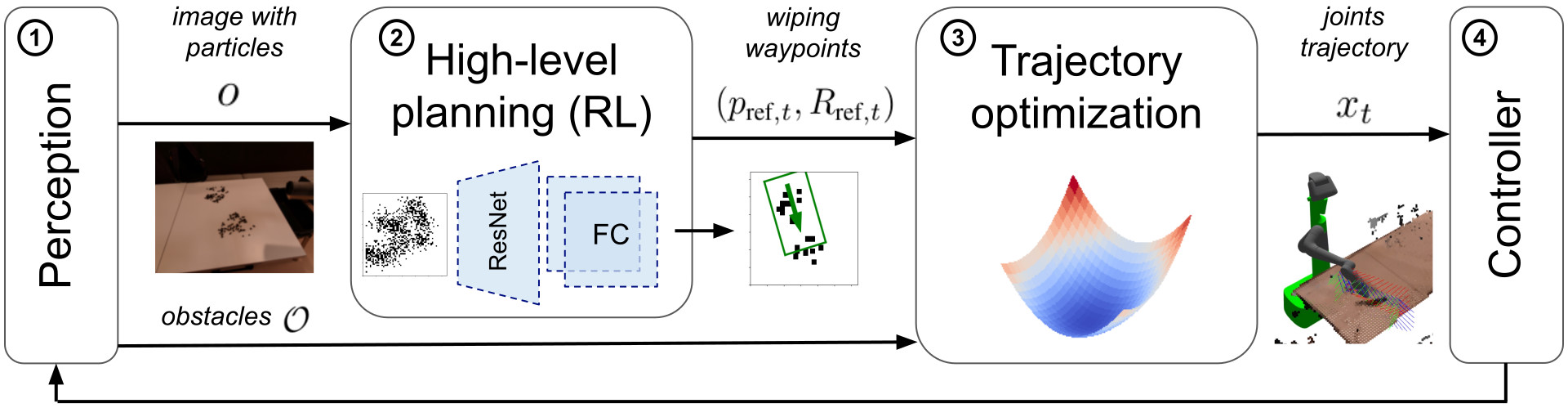
Cleaning requires planning wiping actions while reasoning over uncertain multimodal latent dynamics of crumbs and spills captured via high-dimensional visual observations. To tackle this problem, we first propose a stochastic differential equation (SDE) to model crumbs and spill dynamics and absorption with a robot wiper.
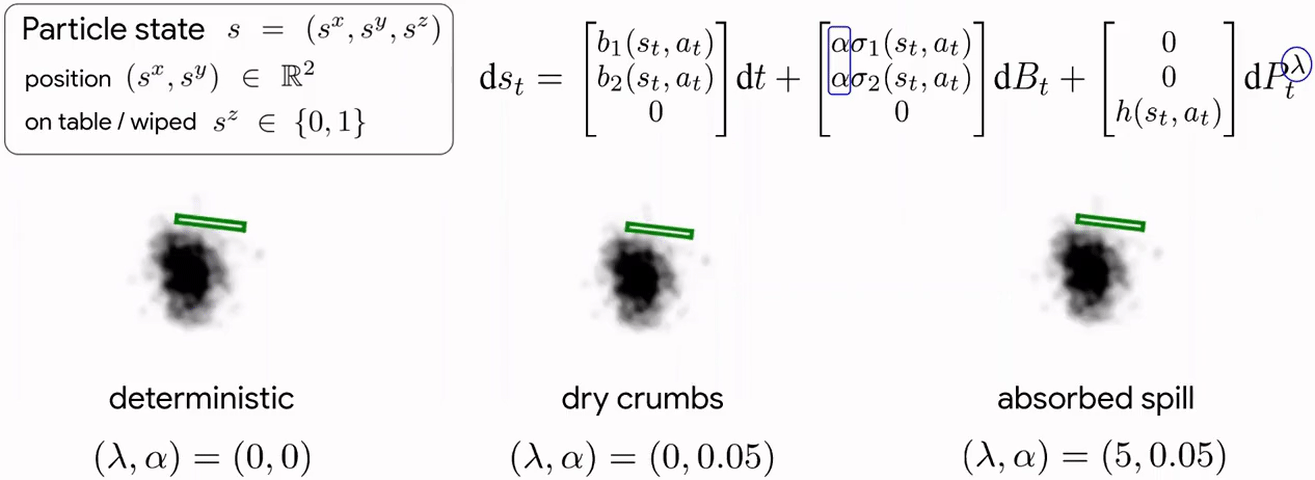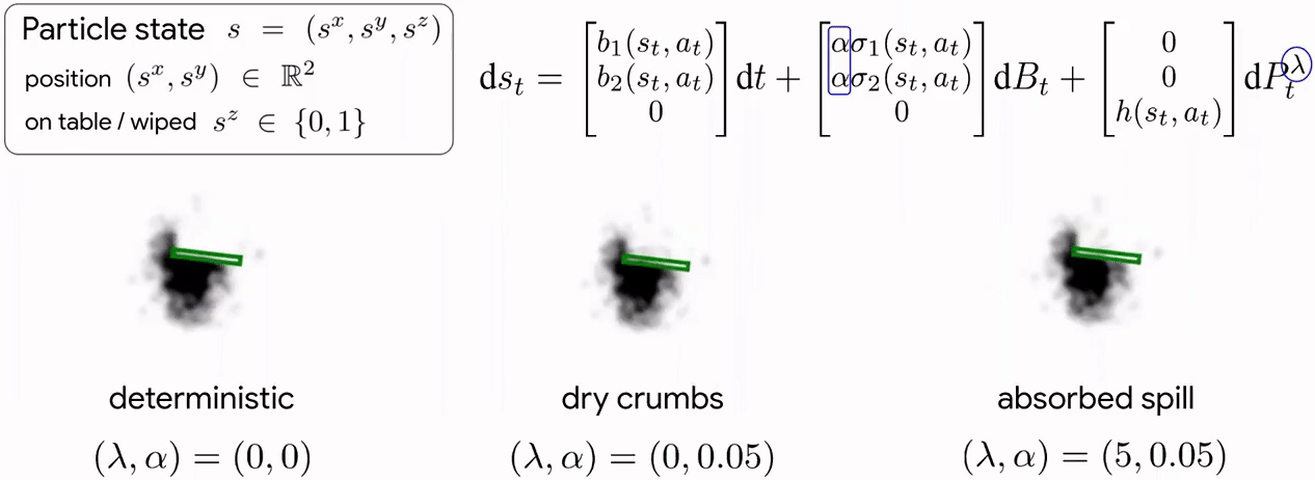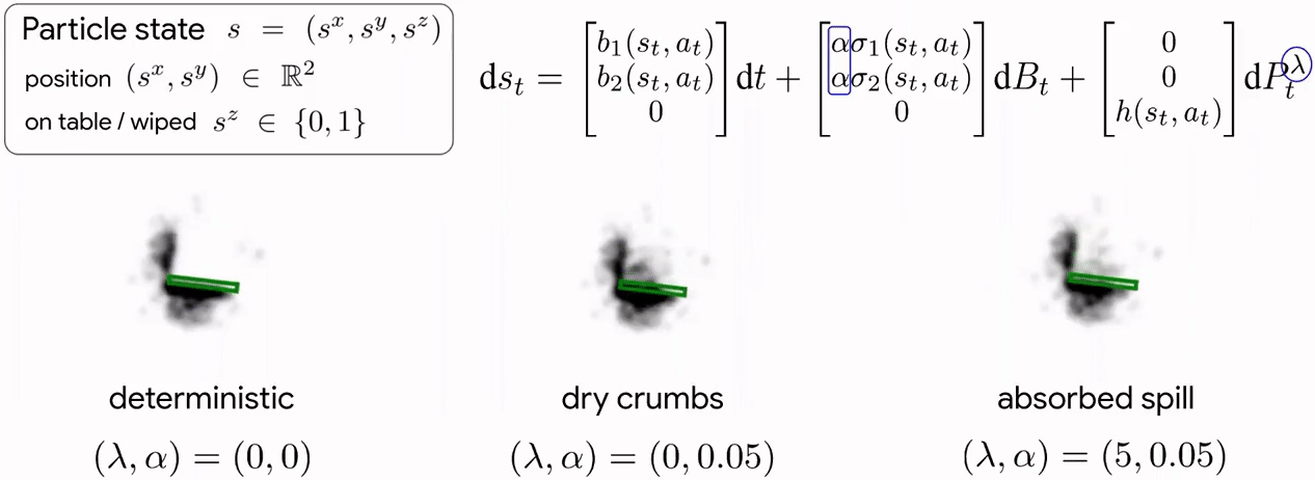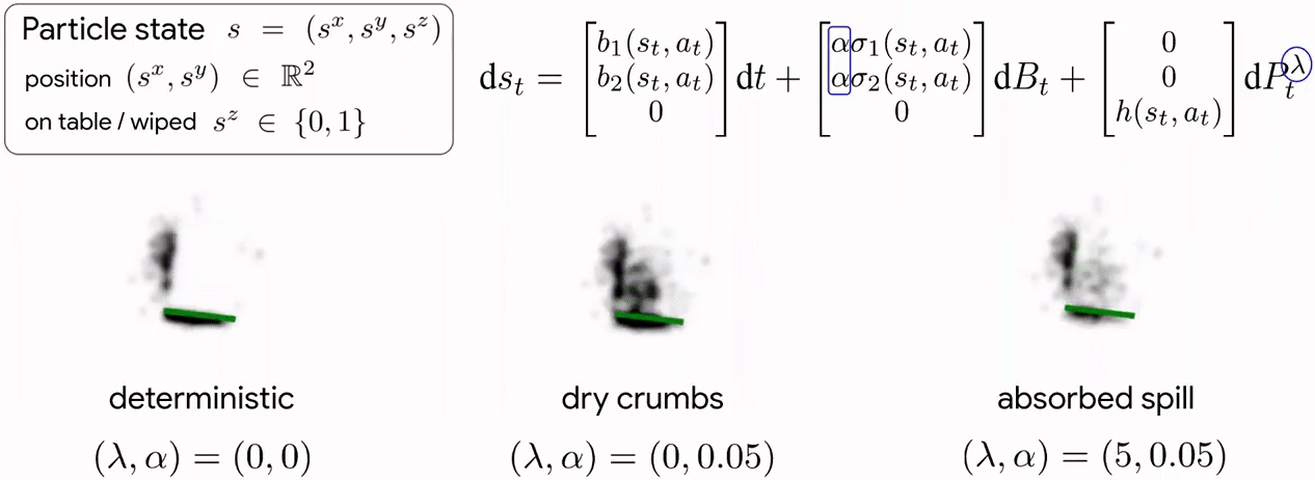
Using this model, we train a vision-based policy for planning wiping actions in simulation using reinforcement learning (RL).
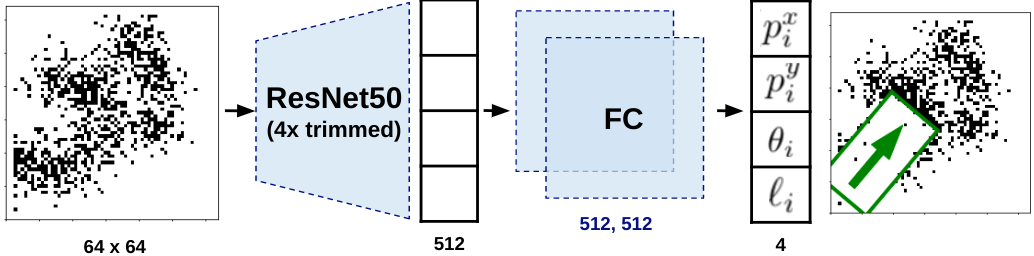
To enable zero-shot sim-to-real deployment, we dovetail the RL policy with a whole-body trajectory optimization framework to compute base and arm joint trajectories that execute the desired wiping motions while guaranteeing constraints satisfaction.

We extensively validate our approach in simulation and on hardware.
